

Overview
A leading EdTech company partnered with our data engineering team to modernize their data pipeline infrastructure. The client faced delays in data availability, limited real-time insights, and difficulties scaling analytics and machine learning workloads due to their traditional batch-oriented ETL pipelines. To overcome these challenges, they aimed to implement a streaming-first, unified data architecture using Microsoft Fabric and its Streaming capabilities to Onelake Lakehouse.
700+
Enterprise Tables Integrated
60M
Records Ingested per Hour
45%
Reduced Manual Effort
27%
Operational Cost Reduction
Customer Challenges
The client’s existing data infrastructure created several obstacles that limited efficiency, scalability, and compliance. To address these challenges, the client required a scalable, streaming-first architecture built on Microsoft Fabric, providing end-to-end support for ingestion, transformation, and secure delivery of data.

Scalable Data Sharing
Lack of a unified platform made it difficult to share data across teams and systems efficiently.

Latency in Data Availability
Traditional batch ETL pipelines delayed the delivery of critical data, slowing time-sensitive decision-making.

Limited Real-Time Analytics
Inability to process streaming data restricted live insights for educators and administrators.

Challenges in Machine Learning Experimentation
Disjointed pipelines and delayed data hindered iterative ML model development and testing.

Compliance & Data Privacy
Managing sensitive student information was complex, with no streamlined approach for secure data handling.
Microsoft Fabric Streaming Architecture for Real-Time Analytics
A streaming-first architecture that ingests data from multiple SQL Server sources into OneLake Lakehouse for real-time analytics and scalable data processing.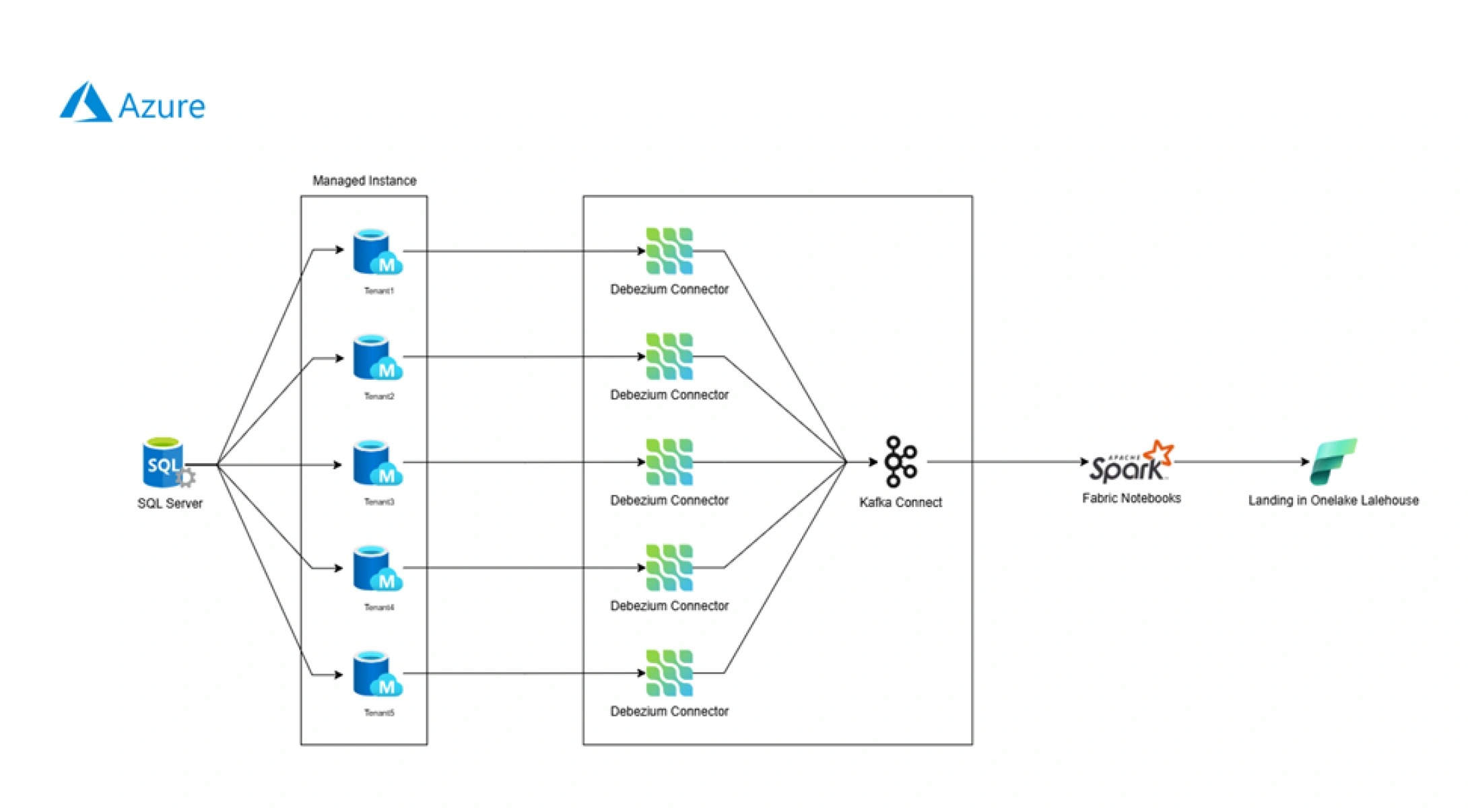
Solutions
Our team designed and implemented a robust streaming data pipeline to ingest, process, and deliver real-time data from over 700 SQL Server tables from multiple databases into Microsoft Fabric’s OneLake Lakehouse. The architecture was built using the following key components
01.
Real-Time Data Ingestion
Kafka and Debezium were used to capture Change Data Capture (CDC) events from SQL Server databases. These events were published to Kafka topics in real-time, enabling continuous data flow from multiple sources without relying on batch processing.
02.
Microsoft Fabric Streaming Integration
The Kafka topics were seamlessly integrated with Microsoft Fabric Streaming Dataflows, which streamed the data directly into OneLake Lakehouse. This integration ensured near real-time availability of raw data, allowing downstream analytics and reporting to be continuously updated.
03.
Data Transformation & Schema Evolution
A multi-layered data architecture was implemented, following a Raw → Bronze transition using Microsoft Fabric’s transformation tools. Schema evolution logic was added to automatically handle changes in source systems, eliminating the need for manual intervention and preventing pipeline downtime.
04.
Data Obfuscation for ML Use Cases
Data masking and obfuscation techniques were applied during transformation to protect sensitive information. This approach enabled secure data sharing with internal machine learning teams, accelerating model development workflows while maintaining compliance and data privacy.
Ready to Ingest Millions of Records Per Hour with a Streaming-First Data Platform?
Schedule a Strategy CallServices




Benefits
Standards-Compliant Architecture
Modular pipeline design using Fabric services enables quick onboarding of new datasets and reduces third-party reliance.
Operational Efficiency Gains
Native Fabric services streamline ingestion, transformation, and storage, improving cost efficiency and consolidating infrastructure.

Streaming Unified Data Platform
Integrated pipelines across SQL Server databases enable near real-time access to transactional and historical datasets.

High-Throughput Ingestion
Ingested millions of records per hour using Microsoft Fabric Streaming, dramatically reducing data latency compared to legacy batch pipelines.
Real-Time Data for ML & Analytics
Transformed and obfuscated data is now available within an hour, accelerating machine learning and analytical workflows.
Automated Schema Evolution
Dynamic schema logic handles frequent source changes, reducing manual engineering effort and maintenance overhead.

Secure Data Sharing
Built-in obfuscation allows safe sharing of sensitive data with internal Machine Learning teams while maintaining compliance.
Conclusion
This case study demonstrates how organizations can leverage Microsoft Fabric Streaming to build modern, secure, and scalable real-time data pipelines. With minimal latency, robust schema handling, and data privacy controls, the solution has laid the groundwork for advanced analytics and AI use cases within the organization.
FAQ
Frequently Asked Questions (FAQs) About Real-Time Data Ingestion Using Microsoft Fabric
How does the solution ensure data privacy and compliance?
Data masking and obfuscation techniques are applied during transformation. This protects sensitive student information while allowing secure access for analytics and internal machine learning teams.
Can this architecture scale for high-volume enterprise data?
Yes. The architecture is designed for high-throughput ingestion (millions of records per hour). It supports hundreds of enterprise tables and can easily onboard new datasets with minimal reconfiguration.
How does this improve machine learning experimentation?
With near real-time, transformed, and obfuscated data available within an hour, data science teams can iterate models faster, test hypotheses efficiently, and reduce experimentation cycles significantly.
Authors



Contact Us
We’d love to hear from you.
Lets discuss how we can transform your business with AI. Talk to our AI expert team. Lets do AI journey together.